Reinforcement Learning (RL), with all its potential applications in fields like Robotics, Autonomous driving, Recommender Systems, etc., is indeed a promising direction. Most of the standard techniques, however, are brittle to small changes in the environment, and this opens up the larger question about generalization in RL. In supervised learning, one of the ways of measuring generalization is by training a model on a training dataset, testing it on a separate dataset drawn from the same independent and identical distribution (i.i.d.), and seeing the performance gap between the two.
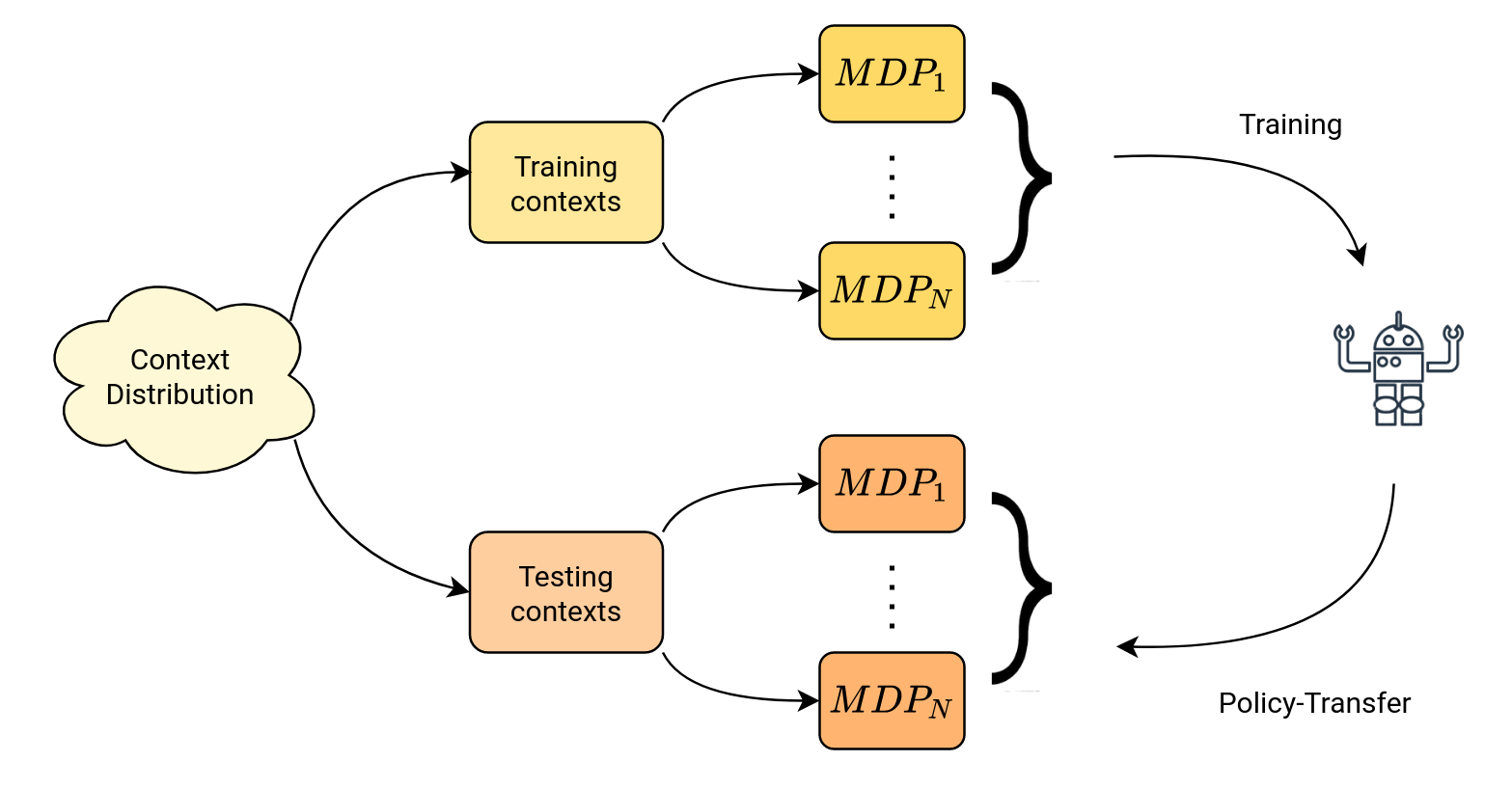
Contextual Reinforcement Learning allows us to extend this idea to the RL setting by talking about distributions on multiple characteristics and properties of the environment. For example, if an agent uses RL to learn a policy that allows it to pick up a cup, then one way of understanding how generalizable this policy is by looking at whether the agent can pick up cups of different sizes, different shapes, or even other objects that are not cups but have similar physical properties. The contextual RL (cRL) setting formalizes this by defining the factors that change (like the size of the handle, the height of the cup, e.t.c) as contexts sampled from a distribution, and each of these contexts creates a separate MDP. These are called contextual MDPs (cMDPs), and they are all essentially variations of the same MDP, differentiated by changing contexts. We can segregate the set of all possible context values into training and testing sets, which allows us to train an RL agent on multiple variations of context features and then analyze its generalization capabilities in a one-shot setting to the environments generated from the test set.
The contextual setting is also of interest for Dynamic Algorithm Configuration (DAC) where we learn policies that dynamically adjust hyperparameters. DAC uses the formalism of cRL to model the requirement for an algorithm to solve many different problems. Moreover, training on a set of tasks and then testing on a held-out set, also called policy transfer, is one of the standard ways to test the performance of algorithms in Multi-Task learning and Meta-Learning.
Our work on cRL
CARL: A benchmark to study generalization in Reinforcement Learning