Can we replace the GP in BO with in-context learning? Absolutely. We achieve strong real-world performance on a variety of benchmarks with a PFN that uses only in-context learning to provide training values. This is what we found out in our ICML ‘23 paper PFNs4BO: In-Context Learning for Bayesian Optimization.
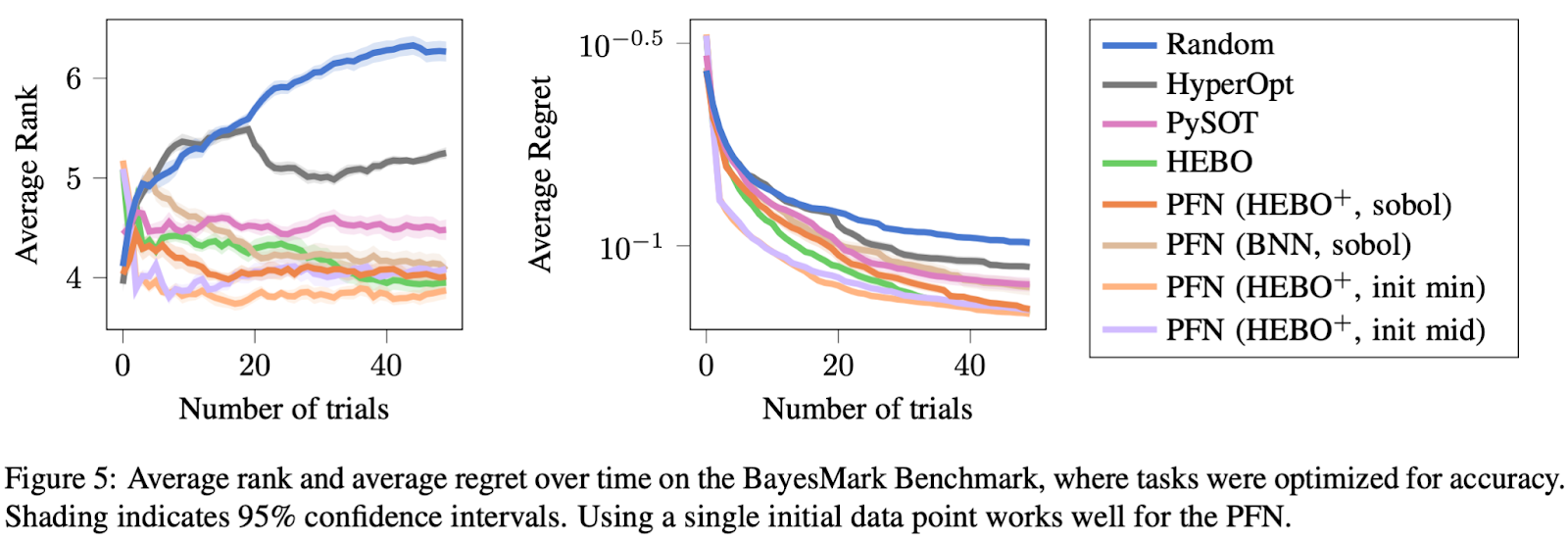
Our models are trained only on data from a prior, i.e. we have not fine-tuned them on real data. Because our models are simple transformers under the hood, we can use them very flexibly. In this work, we use two priors that were not previously available in other posterior approximation methods.
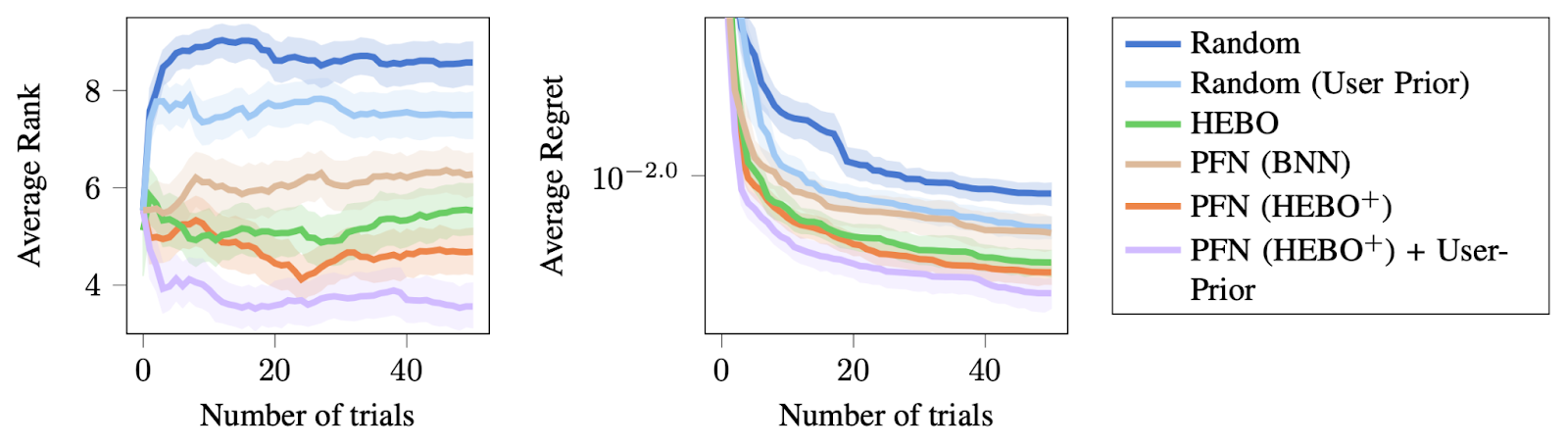
We even show how to allow users to change the prior of a trained model post hoc, by feeding the model a prior over the location of the optimum. If the user sets a reasonable prior, this can significantly improve performance.
Finally, we show how to build the knowledge gradient learning function directly into the neural network. If you want to try our models on your own BO problems, just pip install pfns4bo. Our documentation and training code can be found at https://github.com/automl/PFNs4BO
Our model currently has important limitations. i) The number of parameters of the optimized function has an upper limit of 18 parameters. ii) Our evaluation is very focused on HPO with accuracy as a metric. iii) PFNs tend to perform better for smaller contexts. Therefore, we limit our training to 50 evaluations.