Authors: Tim Ruhkopf, Aditya Mohan, Difan Deng, Alexander Tornede, Frank Hutter, Marius Lindauer
TL;DR: We are augmenting classical algorithm selection with multi-fidelity information, which we make non-myopic through meta-learning – enabling us for the first time to interpret partial learning curves of varying lengths jointly and make good algorithm recommendations at low cost.
Why should I care? – Rethinking Algorithm Selection
Data scientists face the challenge of selecting the best algorithms and configurations, often involving trial and error and high costs. Our MASIF (Meta-learned Algorithm Selection using Implicit Fidelity Information) research revolutionizes algorithm selection by incorporating low-cost fidelity information and interpreting partial learning curves of varying lengths that would otherwise not be fair to compare. By harnessing collective experiences with the algorithms, we simplify the selection of a suitable algorithm by contextualizing cheap test-time evidence effectively – that is, combatting myopia (shortsightedness) inherent in fidelity methods – ultimately leading to better-informed rankings on algorithms at low cost.
In the following sections, we explore MASIF’s driving concepts. We highlight how previous experiences become a valuable resource for algorithm selection. Join us as we uncover the transformative power of experience-driven selection.
The untapped potential in learning curves
Learning curves provide valuable insights into an algorithm’s learning behavior and reflect the algorithm’s success or failure in achieving its task. Critically, their performance trajectory encodes the success of their inductive bias, i.e., the structure the algorithm searches for in the data as it unrolls on a task. If you think about it, on the other hand, this same success also tells us something about the structure of the dataset that the algorithm looks at. Think of it as a landmarking or probing feature with which you can inspect the datasets manifold. Although not explicitly stated in the algorithm selection literature, static dataset meta-features and final landmarking performances of some cheap proxy algorithms seek to create a similar context. In classical algorithm selection, creating such an informative context or experience that is informative of both the inductive bias and the dataset’s structure is a very intricate and manual effort. Aggravating, as we are never allowed to look at the actual algorithms on a new task due to the daunting expenses; there are also no guarantees that we will eventually make a good decision.
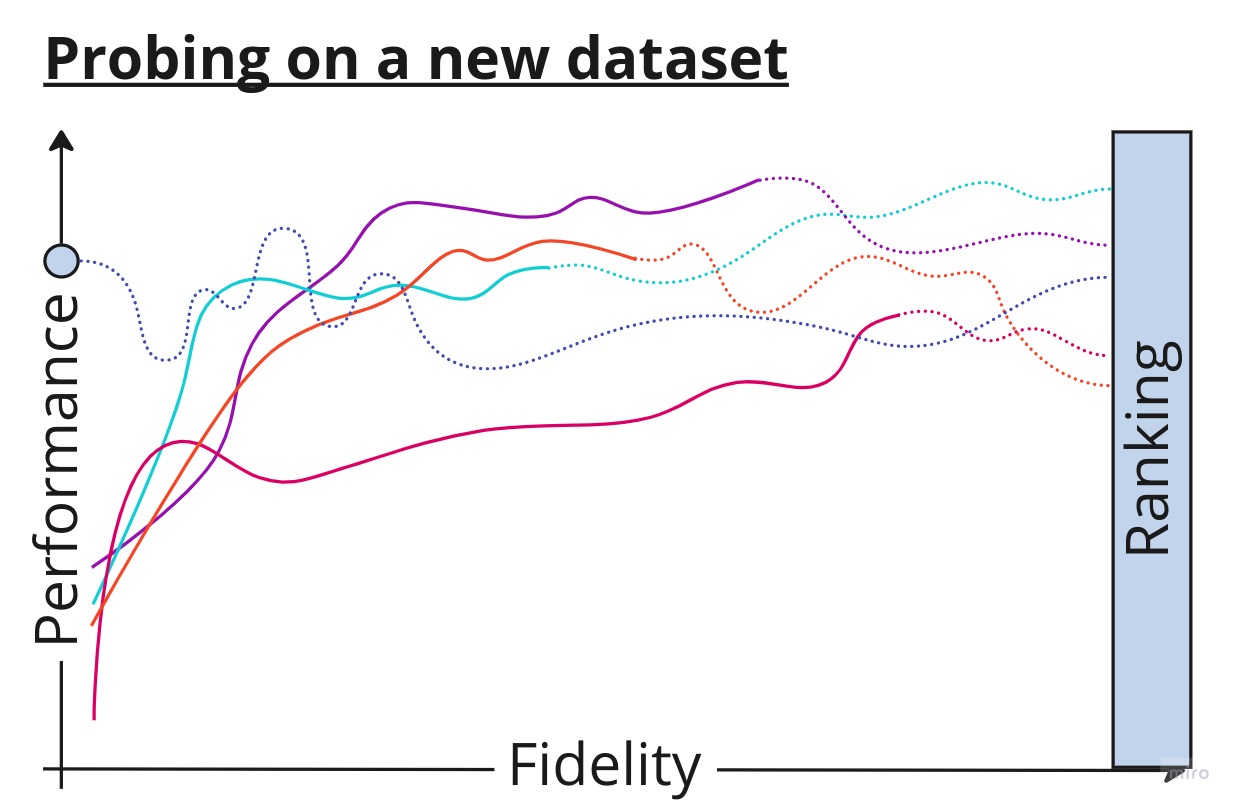
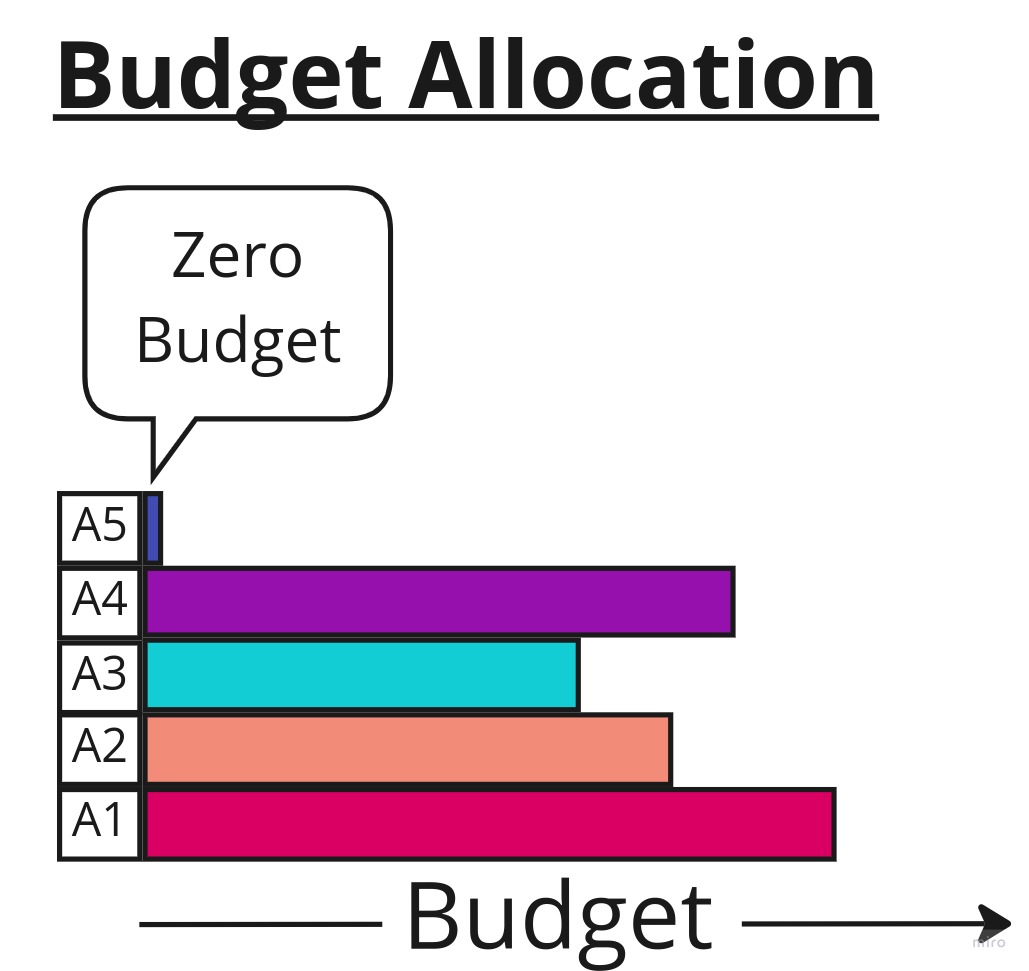
Figure 1: Evaluation of algorithms at multiple fidelities, corresponding to varying length learning curves. We can formulate a belief even for zero allocated budget. But why?
But let’s get back to the multi-fidelity methods for a second. Looking at a single curve with little to no context on the inductive bias nor the dataset’s shape, information about both is mixed and mingled and eventually completely lost in the noise to us. This is what multi-fidelity methods often struggle with, leading them to a strong reliance on the latest trend of the curves, often ignorant of previous experience with the algorithms. Worse, it is also very difficult to fairly compare learning curves at different amounts of fidelity.
The Revolution – Crowd-Sourcing Learning Experience
As data scientists, we have experience with (classes of) algorithms and have a gut feeling when we see a partial learning curve if it is worth continuing and often terminates configurations prematurely in rapid prototyping. Even though we did not invest too much in an inferior configuration, having tried it out, we have gained some evidence for our current dataset. MASIF builds on the very same idea and tries to disentangle the inductive bias from the dataset’s shape. It leverages experience with the candidate algorithms in the form of previous learning curves from previous experiments with them on various tasks. These days, performance data is tracked more rigorously and also published, building a wealth of experience MASIF can draw upon. Its transformer-based architecture first encodes available learning curves from crowd-sourced experiments and then interprets learning curves jointly as distinct views on the dataset. Observing these curves multiple times on different datasets, it learns implicitly to disentangle the inductive bias encoded in the learning curves from the dataset signal. A neat trick to enable MASIF to make sense of any set of partial learning curves is non-uniform max masking during training, which roughly translates to the very relatable setting of a data scientist that tries out multiple algorithms and terminates them at different points in time. In this scenario, the data scientist actively gathers online evidence about his selection evidence in light of his experience with the algorithms. This experience can even include classical dataset meta-features.
By considering the online evidence from multiple candidates in their respective partial learning curves, MASIF can infer how the inductive biases unroll – even for unseen candidates. This approach eliminates the need to examine every learning curve under the same budget and ensures fair comparisons in the light of the given online evidence & experience.
Interpretation vs Scheduling
One important detail of MASIF, which is both a blessing and a limitation of our current work, is that MASIF is only interpreting partial learning curves from online evaluations – eventually providing its current belief – and not scheduling which algorithm to evaluate up to which fidelity. While it has very strong performance early on with little to no fidelity, even on noisy datasets, as Figure 2 suggests, the ultimate decision of what to evaluate next to improve the final ranking is left to the user.
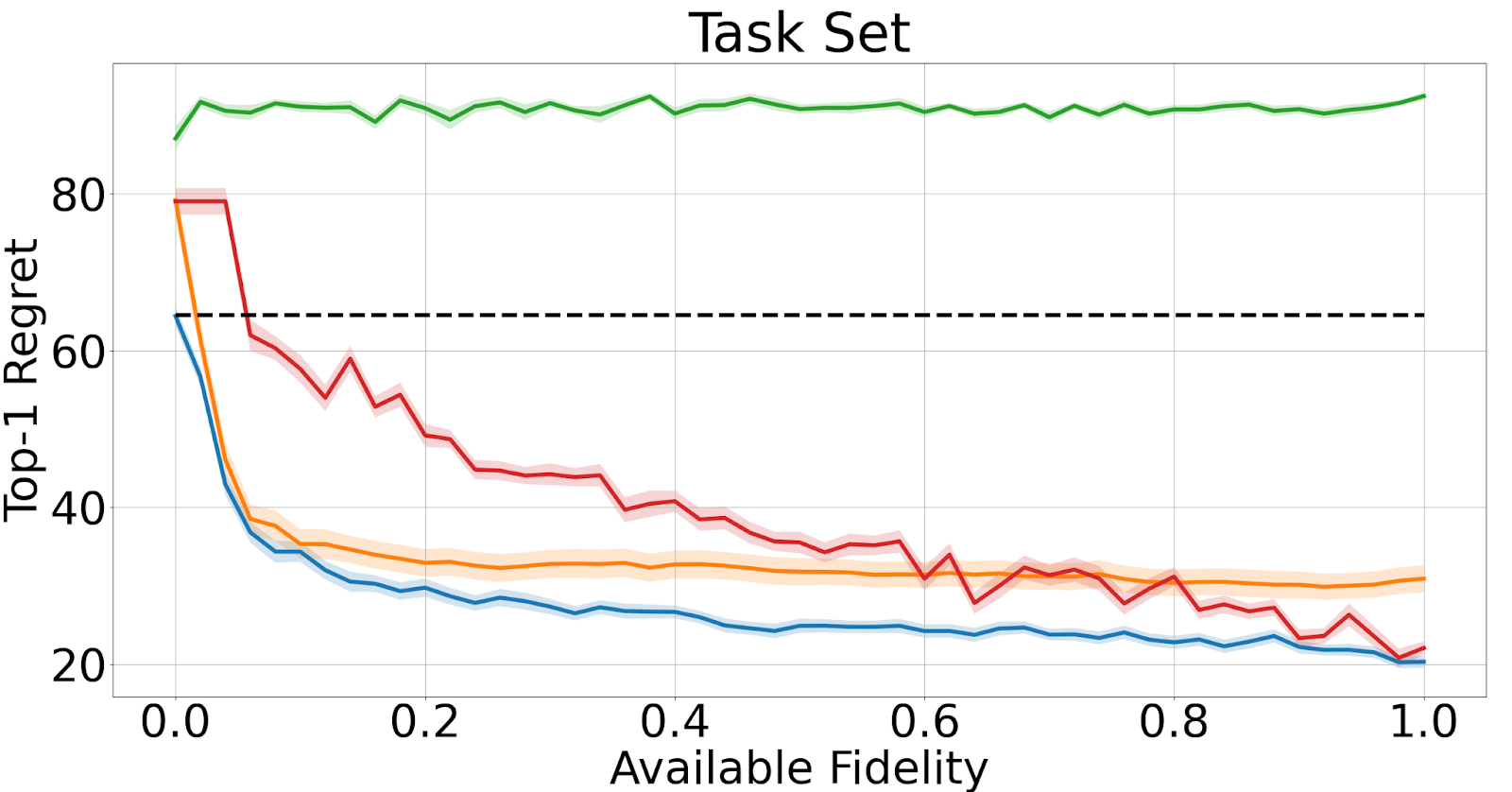
Figure 3: The slice evaluation protocol on the noisy learning curve benchmark Task Set. Iteratively expanding the amount of fidelity (fidelity-horizon) the meta-learner is allowed to use for its ranking prediction. Notice that Successive Halving, due to its rigid scheduler, is allowed to evaluate considerably less, at lower costs, but performs considerably worse.
There is, however, also a more uplifting perspective; since MASIF is only providing its current belief, it can readily be used in a plug-in fashion for many multi-fidelity methods, which we demonstrate with the popular Successive Halving method and gain considerably better performance due to the meta-experience.
Conclusion
We use the experience to combat myopia in learning curves effectively and created a plug-in-play method that enables data scientists to make smarter scheduling decisions that are based on the crowd-sourced experience with their algorithms. Our method neatly bridges multi-fidelity methods and classical algorithm selection to benefit both. Namely, the multi-fidelity aspect no longer needs to be myopic about its belief, and the classical algorithm selection is allowed to cheaply evaluate the candidate algorithms due to the multi-fidelity angle, giving strong selection recommendations even when classical dataset meta-features are insufficient characterizations.
For more details, please check out our TMLR paper at Openreview.