 Strong image classification models need augmentations. That is consensus in the community for a few years now. Some augmentation choices became standard over the time for some datasets, but the question what augmentations strategy is optimal for a given dataset remained. This opened the opportunity of doing hyper-parameter optimization (HPO) to find optimal augmentation choices. The AutoAugment method by Cubuk et al. was the first to treat this problem as an HPO problem. AutoAugment outperformed the standard augmentations for each dataset studied and yielded new state-of-the-art performances. It turned out to be very expensive, though: their reinforcement learning based setup required thousands of evaluations. Therefore, a lot of work followed that lowered the computational cost of finding similarly well-performing augmentation strategies. While so far this story might sound very valid and logical, we found something curious when we started working in this field. At some point we implemented the most trivial baseline we could come up with as a sanity check, and it outperformed all other methods we considered. We then went ahead and implemented multiple other automatic augmentation methods, like AutoAugment, in our setup and added more datasets and models to our experiments; the as-easy-as-possible baseline kept being strongest.
Strong image classification models need augmentations. That is consensus in the community for a few years now. Some augmentation choices became standard over the time for some datasets, but the question what augmentations strategy is optimal for a given dataset remained. This opened the opportunity of doing hyper-parameter optimization (HPO) to find optimal augmentation choices. The AutoAugment method by Cubuk et al. was the first to treat this problem as an HPO problem. AutoAugment outperformed the standard augmentations for each dataset studied and yielded new state-of-the-art performances. It turned out to be very expensive, though: their reinforcement learning based setup required thousands of evaluations. Therefore, a lot of work followed that lowered the computational cost of finding similarly well-performing augmentation strategies. While so far this story might sound very valid and logical, we found something curious when we started working in this field. At some point we implemented the most trivial baseline we could come up with as a sanity check, and it outperformed all other methods we considered. We then went ahead and implemented multiple other automatic augmentation methods, like AutoAugment, in our setup and added more datasets and models to our experiments; the as-easy-as-possible baseline kept being strongest.
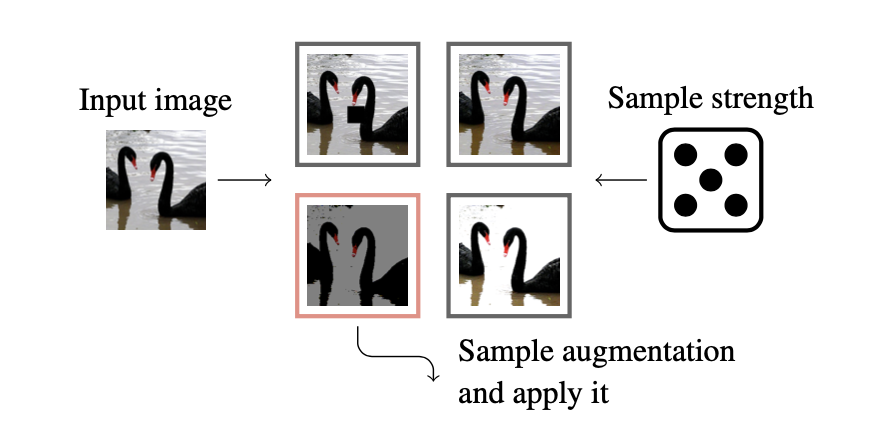
We named this baseline TrivialAugment (TA): Without tuning, as cheap as possible, and trivial to describe, but posing the strongest scores in multiple key benchmarks. The image above visualizes TA and Algorithm 1 shows what TA does in pseudo code.

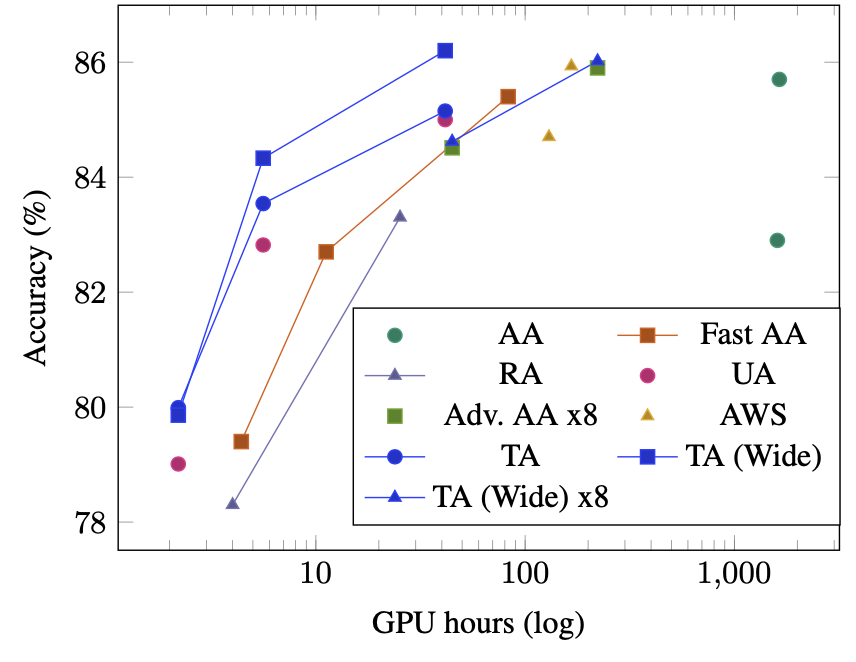
We sample the strength from a uniform distribution, as is often done in standard augmentation pipelines, but we also sample the augmentation itself (a fresh sample of both augmentation and strength for each image) and only apply a single augmentation per image. Below we show how it compares to other standard algorithms. Although TA is simple and cheap, it outperforms the other methods on most benchmarks.
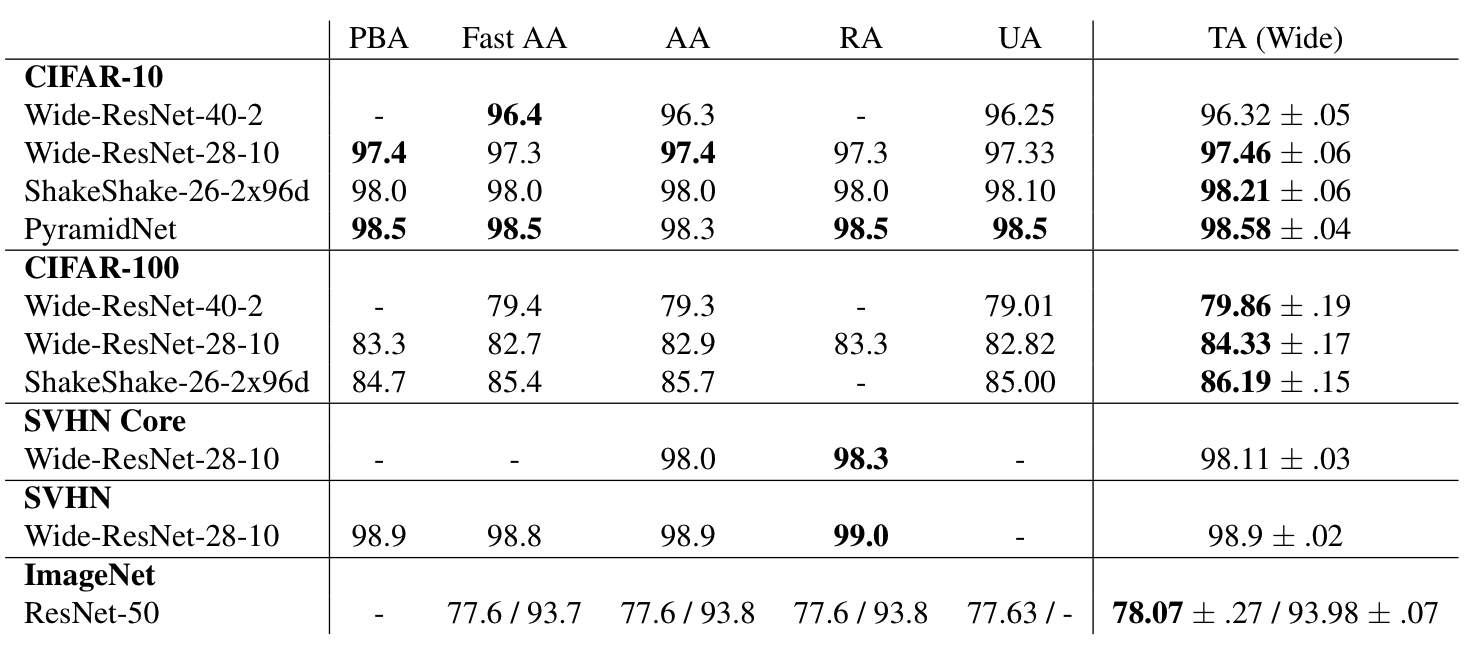
Below we compare the computational budget in GPU hours to the final accuracy on CIFAR-100 across augmentations strategies and neural network models. We can clearly see that TA outperforms all previous methods in this tradeoff. That means, given a certain amount of compute, TA can yield models with the highest accuracy, compared to previous methods. This evaluation is across models and across setups (some of the works we compare to use different numbers of epochs). If we caught your interest, see the full paper, which just got accepted to ICCV 2021 as an oral presentation!
If you just want to drop TrivialAugment into your code or build on our setup, please have a look at our repo.